Subject
Personal academic research subject: Share research results, learning experiences and project progress in the field of AI, with particular attention to the intersection of business and artificial intelligence technology. For every scholar who loves to explore artificial intelligence technology, especially those colleagues who are interested in machine learning, deep learning and natural language processing, this is an ideal personal study and communication platform.
At this platform, you will find a wealth of information on the latest research achievements, learning experiences, and project progress in the field of AI. We are committed to advancing knowledge at the interface of business and artificial intelligence technology. For instance, our researchers delve into how AI can revolutionize supply chain management by predicting demand more accurately, optimizing inventory levels, and improving logistics efficiency. They also investigate the role of AI in enhancing customer experience through personalized recommendations and real-time support.
Our program places a strong emphasis on exploring the intersection of business and artificial intelligence technology. We believe that the fusion of these two domains holds immense potential for creating value and driving innovation. By leveraging AI, businesses can gain deeper insights into market trends, consumer behavior, and operational inefficiencies. This enables them to make data-driven decisions, streamline processes, and develop new products or services that meet evolving customer needs.
For scholars who are passionate about delving into the intricacies of artificial intelligence technology, this platform offers an ideal environment for communication and collaboration. Whether your interests lie in machine learning, deep learning, natural language processing, computer vision, or robotics, you will find a vibrant community of like-minded individuals here. Our postdoctoral fellows come from diverse academic backgrounds and bring unique perspectives to the table. They engage in interdisciplinary research projects that push the boundaries of what is possible in both AI and business.
Our postdoctoral fellows engage in groundbreaking research that bridges the gap between theoretical advancements and practical applications in the business world. They explore how AI can enhance decision-making processes by providing predictive analytics and actionable insights. For example, AI algorithms can analyze vast amounts of financial data to identify patterns and forecast market trends, helping businesses make informed investment decisions. In addition, AI can optimize operations by automating routine tasks, reducing human error, and improving productivity. Furthermore, it can create new business models by enabling the development of innovative products and services that leverage AI capabilities.
Through case studies, real-world examples, and collaborative projects, our researchers demonstrate the transformative potential of AI in various industries. They work closely with industry partners to identify challenges and co-create solutions that address real-world problems. For instance, in the healthcare sector, AI can assist in diagnosing diseases more accurately and personalizing treatment plans based on patient data. In the retail industry, AI can optimize pricing strategies and enhance customer engagement through personalized marketing campaigns.
We also provide resources and support for those looking to deepen their understanding of AI and its applications in business. From workshops and seminars to publications and conferences, we strive to create an enriching environment that fosters innovation and knowledge sharing. Our workshops offer hands-on training in AI tools and techniques, while our seminars feature guest speakers from academia and industry who share their expertise and insights. Our publications disseminate research findings and best practices to a wider audience, and our conferences bring together thought leaders and practitioners to discuss emerging trends and challenges in the field.
Join us on this exciting journey as we continue to push the boundaries of what is possible at the intersection of artificial intelligence and business. Together, we can unlock new opportunities, solve complex problems, and shape the future of industries through the power of AI and collaboration.
Projects
Deep Learning-Based Sentiment Analysis Model
During my postdoctoral research at the Massachusetts Institute of Technology, I had the opportunity to discuss with professors the application impact of AI scientific research achievements in the business field. Among them, a notable project was the development of a sentiment analysis tool. This tool can automatically identify the sentiment tendency in text, such as positive, negative or neutral, providing users with real-time sentiment analysis services. It has broad application prospects in areas such as social media monitoring and brand reputation management. To build this sentiment analysis model, we chose the Python programming language and used the TensorFlow and Keras libraries to construct a Long Short-Term Memory (LSTM) network, a special type of Recurrent Neural Network (RNN). LSTM effectively solves the vanishing gradient problem that traditional RNNs encounter when processing long sequence data by introducing "memory cells" and "gate mechanisms", thereby better capturing long-term dependencies in text. Specifically, LSTM can maintain a high accuracy rate when processing long sentences. During the training process, we collected a large number of social media posts and comments as the dataset. Through a carefully designed data preprocessing process, including removing stop words and word segmentation operations, the original text was transformed into a format suitable for model input. In addition, we used word embedding techniques such as Word2Vec or GloVe to convert words into vector representations, further enhancing the model's expressiveness. After multiple iterations of training, the model gradually learned to recognize emotional expressions in different contexts, such as accurately identifying the hidden emotional tendency from a seemingly plain comment, providing users with reliable sentiment analysis results. Moreover, we conducted model evaluation and optimization, ensuring the stability and accuracy of the model in practical applications through cross-validation and hyperparameter tuning.
During my postdoctoral research at the Massachusetts Institute of Technology (MIT), I was fortunate to engage in insightful discussions with leading professors on the practical applications and impact of artificial intelligence (AI) advancements in the business world. These interactions provided a wealth of knowledge and inspiration, fostering an environment conducive to innovation. One particularly noteworthy project that emerged from these discussions was the development of a deep learning-based sentiment analysis model. This cutting-edge tool has the capability to automatically detect and categorize the emotional tone within textual content, classifying it as positive, negative, or neutral. By offering real-time sentiment analysis services, this model provides significant value across various industries, especially in social media monitoring and brand reputation management.
The importance of understanding public sentiment cannot be overstated in today's digital age. Companies rely heavily on consumer feedback to make informed decisions, improve products, and enhance customer experiences. The ability to analyze vast amounts of unstructured data from social media platforms, customer reviews, and online forums is crucial for businesses seeking to stay competitive. Our sentiment analysis model addresses this need by providing actionable insights into how people feel about brands, products, and services.
To construct this sentiment analysis model, we chose Python, a versatile and widely-used programming language in the data science community. Python's extensive libraries and frameworks make it an ideal choice for developing complex machine learning models. We leveraged two powerful libraries, TensorFlow and Keras, to build a Long Short-Term Memory (LSTM) network, which is a specialized form of Recurrent Neural Network (RNN). The LSTM architecture addresses one of the main challenges faced by traditional RNNs when dealing with long sequences of data: the vanishing gradient problem. By incorporating "memory cells" and "gate mechanisms," LSTMs can effectively retain information over longer periods, allowing them to capture intricate dependencies within text more accurately. This feature is particularly advantageous when processing lengthy sentences, where maintaining context and coherence is crucial.
In order to train the model, we gathered an extensive dataset comprising a vast array of social media posts and comments. These sources provided a rich and diverse pool of textual data, reflecting a wide spectrum of human emotions and expressions. A meticulous data preprocessing pipeline was established to prepare the raw text for model input. This process involved several steps, including the removal of stop words—common terms that do not contribute significantly to the meaning of a sentence—and word segmentation, which breaks down text into individual components for easier analysis. Additionally, we employed word embedding techniques such as Word2Vec and GloVe to transform words into vector representations. These embeddings capture semantic relationships between words, thereby enhancing the model's ability to understand and interpret nuanced emotional cues.
Through multiple rounds of training, the model progressively refined its ability to discern emotional nuances in different contexts. For instance, it became adept at identifying subtle emotional undertones in seemingly neutral comments, delivering reliable and accurate sentiment analysis results to users. To ensure the robustness and reliability of the model, we conducted rigorous evaluations and optimizations. Techniques such as cross-validation and hyperparameter tuning were employed to fine-tune the model's performance, ensuring its stability and accuracy in real-world applications. This comprehensive approach enabled us to develop a sentiment analysis tool that not only meets but exceeds the demands of modern businesses seeking to gain deeper insights into public sentiment.
Moreover, the model's adaptability allows it to be customized for specific industries and use cases. For example, in the financial sector, sentiment analysis can help predict market trends by analyzing investor sentiment expressed in news articles and social media. In healthcare, it can assist in monitoring patient feedback to improve service quality. In retail, it can provide valuable insights into customer preferences and satisfaction levels. The versatility of our sentiment analysis model makes it a valuable asset for businesses across various sectors, enabling them to make data-driven decisions and stay ahead of the competition.
II. Intelligent Image Recognition System
In addition to my other responsibilities, I was actively involved in the development of an intelligent image recognition system specifically designed for medical image diagnosis. The primary objective of this project was to assist doctors in diagnosing diseases more quickly and accurately by leveraging advanced machine learning techniques. This system is particularly useful for detecting tumors, lesions, and other abnormalities from medical imaging modalities such as X-rays, CT scans, MRIs, and ultrasounds.
Given the unique characteristics of medical image data, which often contain complex patterns and require high precision, we chose convolutional neural networks (CNNs) as the core technology for feature extraction. CNNs are renowned for their strong local perception capabilities and parameter sharing mechanisms, making them exceptionally well-suited for processing two-dimensional image data. These networks can automatically learn hierarchical features from raw images, which is crucial for identifying subtle changes that may indicate disease.
However, one of the major challenges we faced was the limited availability of labeled medical image datasets. Medical images are often scarce due to privacy concerns and the high cost of acquiring and annotating them. To overcome this limitation, we implemented a transfer learning strategy. Transfer learning allows us to leverage pre-trained models that have been trained on large-scale general image datasets, such as ImageNet, which contains millions of labeled images across thousands of categories. By fine-tuning these pre-trained models on our specific medical image dataset, we were able to significantly improve the model's performance while reducing the need for extensive labeled data. This approach not only accelerates the training process but also enhances the model's generalization ability, especially in scenarios where the sample size is small.
For example, we first pre-trained the CNN model on ImageNet to ensure it had a robust understanding of general image features. We then fine-tuned the model using a smaller, specialized dataset of medical images, adjusting the network parameters to better capture the unique characteristics of these images. This hybrid approach allowed us to achieve state-of-the-art performance in detecting various types of medical conditions, including early-stage cancers and rare diseases.
Beyond the technical aspects, we also placed significant emphasis on improving the user experience for healthcare professionals. Recognizing that doctors often work under time constraints and may not be familiar with complex machine learning algorithms, we developed a user-friendly graphical user interface (GUI). This GUI enables doctors to easily upload patient images and obtain analysis results with minimal effort. The entire process is designed to be simple and intuitive, ensuring that even those with limited technical expertise can use the system effectively. For instance, doctors can simply drag and drop a patient's X-ray or CT scan into the designated area, and the system will promptly provide an initial diagnosis. This immediate feedback helps streamline the diagnostic process and supports the formulation of subsequent treatment plans.
Furthermore, we prioritized the scalability and security of the system to ensure its long-term viability. To handle the large volume of data generated by medical imaging, we adopted distributed computing frameworks such as Apache Spark, which allow for efficient parallel processing. Additionally, we implemented robust encryption technologies to protect sensitive patient information, adhering to strict data privacy regulations. By ensuring both performance and security, we aimed to build a system that could be trusted by medical institutions worldwide.
To continuously improve the accuracy and reliability of the model, we collaborated with multiple medical institutions to gather and update data regularly. This ongoing collaboration ensures that the system remains up-to-date with the latest medical knowledge and practices. Moreover, it allows us to incorporate feedback from doctors and refine the model based on real-world usage, further enhancing its diagnostic capabilities.
In summary, the intelligent image recognition system we developed represents a significant advancement in medical diagnostics. By combining cutting-edge machine learning techniques with a focus on user experience and data security, we have created a tool that not only improves diagnostic accuracy but also enhances the efficiency of healthcare delivery.
III. Chatbot Assistant
At the same time, my professor team and I are also dedicated to developing a chatbot assistant. The primary objective of this chatbot is to provide users with a natural and smooth conversation experience, whether they are seeking assistance in daily life or looking for professional knowledge. To achieve this goal, we have employed advanced natural language processing (NLP) technology and sophisticated intent recognition algorithms to accurately parse users' questions.
When a user poses a question, the chatbot first employs NLP techniques to understand the underlying intent and context. It then generates an appropriate response based on a comprehensive pre-defined knowledge base that encompasses a wide range of topics, from general information to specialized domains. For more complex queries, the chatbot can seamlessly integrate API interfaces to call external services, such as booking a restaurant, checking the weather forecast, or even providing real-time traffic updates. This not only enhances user satisfaction by offering practical solutions but also expands the application scenarios of the chatbot, making it a versatile tool for everyday use.
For instance, users can utilize voice commands to ask the chatbot to help find nearby restaurants and recommend the best options based on ratings, distance, dietary preferences, and even current promotions. The chatbot can also assist with travel planning by suggesting optimal routes, checking flight availability, and providing hotel recommendations. In terms of technology selection, we chose Python as the main programming language due to its extensive libraries and community support for NLP tasks. We utilized NLP platforms like Rasa or Dialogflow to simplify the development process and ensure robust performance.
Additionally, to ensure the chatbot can run stably and provide a seamless interaction experience, we integrated web frameworks such as Flask or Django for deployment on the server side. These frameworks allow us to efficiently manage server resources and serve a larger number of users simultaneously. Moreover, we have paid special attention to the functions of multi-round dialogue management and context understanding. By introducing dialogue state tracking (DST) and dialogue management (DM) modules, the chatbot can maintain coherence and consistency in multi-round conversations.
For example, when a user asks for detailed information about a certain product, the chatbot can continue the discussion around that product in subsequent conversations without topic jumps or information loss. It can also remember previous interactions and adapt its responses accordingly, ensuring a personalized and engaging experience. Furthermore, the chatbot is designed to handle interruptions and ambiguous queries gracefully, providing clarifications when necessary and guiding users through complex processes step by step.
In summary, our chatbot assistant aims to offer a comprehensive and intuitive conversational interface that can cater to a wide variety of user needs, from simple inquiries to intricate problem-solving tasks. Through continuous improvement and integration of cutting-edge technologies, we strive to create a chatbot that not only meets but exceeds user expectations in terms of functionality, reliability, and user experience. If you have a keen interest in the integration of artificial intelligence (AI) in both the business and academic fields, we invite you to share your thoughts and engage in a meaningful discussion. AI has become an increasingly important tool that is transforming industries and research areas alike.
In the business world, AI is being used to streamline operations, improve customer service, and drive innovation. For example, companies are leveraging AI algorithms to analyze vast amounts of data, enabling them to make more informed decisions and identify new opportunities. AI-powered chatbots are enhancing customer interactions by providing instant responses and personalized recommendations. Additionally, AI is revolutionizing supply chain management by optimizing inventory levels and predicting demand fluctuations.
In academia, AI is opening up new avenues for research and discovery. Researchers are utilizing machine learning techniques to process complex datasets and uncover patterns that were previously undetectable. This has led to breakthroughs in fields such as healthcare, where AI is assisting in diagnosing diseases and developing personalized treatment plans. Moreover, AI is facilitating interdisciplinary collaborations, bringing together experts from different domains to tackle challenging problems.
By leaving your comments, you can contribute to this ongoing dialogue and exchange ideas with others who share similar interests. Whether you have insights on the latest AI applications, concerns about ethical considerations, or suggestions for future developments, your input is valuable. Let’s explore the potential of AI together and shape its role in shaping the future of business and academia.
Main courses content sharing
This article, which stems from the Martin Trust Center for MIT Entrepreneurship, is penned by Jim Dougherty who delivered the lecture. The Martin Trust Center for MIT Entrepreneurship is a prestigious hub at the Massachusetts Institute of Technology that fosters an environment conducive to entrepreneurial activities and innovation. It provides resources, mentorship, and funding opportunities to students and entrepreneurs alike, aiming to transform groundbreaking ideas into viable businesses. Jim Dougherty, as an experienced professional in the field of entrepreneurship, brings a wealth of knowledge and practical insights to his lecture. His expertise covers various aspects of starting and running a successful business, such as identifying market needs, developing business models, securing investments, and overcoming challenges. Through real - life examples and case studies, he illustrates the key principles and strategies that contribute to entrepreneurial success. Moreover, his lecture also touches upon the importance of perseverance, adaptability, and collaboration in the ever - evolving business world.
MADAKET HEALTH
It finally felt like spring after a record-breaking snowy winter in Boston, and many were celebrating by watching the 2015 Red Sox home opener. In his new office in Harvard Square, Jim Dougherty chuckled at Patriots' Tom Brady's attempt at an opening pitch and reflected on his Red Sox dilemma of Fall 2013. A die-hard fan, Jim had tickets for Game 6 of the World Series, purchased long before it was clear whether or not the Sox would get to that game. When it became clear that the Red Sox could win the World Series at Fenway - which had not occurred since 1918 – he realized he had a conflict. Many weeks before, Jim had finally secured an out-of-town meeting with a very large prospect for his health technology start-up, Madaket Health (herein Madaket). While it was tempting to reschedule, Jim ended up foregoing his ticketsto the (winning) game to pitch his start-up instead.
Though it had been a painful decision at the time, Jim was proud of his choice. He was now finalizing a valuable contract with the prospect he had begun cultivating at that meeting. In the past months he had closed a favorable Series A financing round, began launching a commercial version of his product and grown his team to 17 FTE. With this new bandwidth and runway, he and his team wanted to clarify Madaket's customer strategy. Within the health payments industry, who should Madaket target first? How should they think about customer sequencing? What were the benefits and costs to concentrating on each potential customer group?
Symptoms: Restless Entrepreneur
Jim Dougherty was a restless entrepreneur. A successful entrepreneur and chief executive, Jim had not only scaled several start-ups, he also helped to propel new businesses towards impact as a Senior Lecturer in MIT's Entrepreneurship Lab (E-Lab)
This case was developed by Scott Stern, Kenny Ching and Jane Wu solely for the purposes of classroom discussion. It is not intended to illustrate either effective or ineffective handling of an administrative situation, nor as a source of data. Some case details have been adapted to facilitate the learning objectives of the case. It should not be quoted, reproduced, distributed, or shared in hard copy, electronic or any other form without express permission from the authors. Feedback is welcome to sstern@mit.edu. Copyright 2019
class.' Having moved backed to Boston after selling his enterprise software start-up MetaMatrix to Red Hat, Jim felt that the time had come for him to found a new venture. Jim wanted his new venture to leverage his entrepreneurial and professional experiences in enterprise software in a new market undergoing dramatic change. Jim focused on his experiences at a number of companies over the past two decades, including Lotus, Gartner, MetaMatrix, and a company called Intralinks. As Chairman and CEO of Intralinks 10 years earlier, Jim had witnessed how software solutions could fundamentally change the existing process of document exchange in a traditional industry. Intralinks, a "software as a service" (SaaS) provider that extended collaboration beyond firewalls, had been instrumental in turning what were previously manual processes involving packages and couriers in the banking sector into highly efficient and secure digital transactions. Under Jim's leadership, Intralinks had developed a flexible software architecture, which allowed it to quickly iterate on customer feedback. Through multiple prototypical collaborations with potential customers, Intralinks developed clearer insights and learnings from the market than any of its competitors and built a platform that customers could easily use to solve problems that they currently tolerated but did not have the bandwidth to fix. In the process, Intralinks revolutionized the banking industry.
An area Jim had both read and discussed at length with his colleagues about was the healthcare space. The Affordable Care Act would require the entire industry to undergo dramatic change; health care would face more cost pressures than ever before as well as strong governmental incentives to improve efficiency. Jim saw the great potential to bring about positive change, especially through healthcare IT, which would leverage his past experience and deep expertise in producing enterprise software.
For the next few months, he started hunting around the healthcare eco-system, looking for potential problems to solve. After numerous interviews with stakeholders, and observing emerging changes in the number of insured and methods of reimbursement, Jim concluded that there were excellent opportunities in the US healthcare payment system — this was the place for him to start.
Diagnosis: Opportunities in the US Healthcare Payment System
At its heart, the US healthcare payment system centers around 3 main constituents: private insurance companies and the US government (the "payers"), healthcare
I E-Lab (15.399) focuses on projects where students work with local innovation-based start-up companies on a semester-long project aimed at accelerating those ventures.
providers including physicians, physician assistants and nurse practitioners ("providers"), and patients. Amongst these 3 constituents, there are three streams of money: the payment of money by companies and patients for insurance coverage (premiums to payers); the reimbursement by payers to providers for healthcare services provided, and copayments made by patients to providers at the point of care. More than $3 trillion flows through the U.S. Healthcare Payment System each year."
In evaluating this system, Jim recognized an opportunity in the area of "physician enrollment." For a physician to be reimbursed by an insurer, that physician must go through several steps, including a process called credentialing (where the payer receives information about the physician's medical degrees, years of experience, etc.) and enrollment (where the physician provides the information required by a given insurer to begin claims processing). Nearly all physicians must enroll with multiple insurers, and the roster of insurers a physician enrolls with changes over time (since different patients have different payers).
The as-is state for the enrollment process is highly unwieldy for both payers and providers. Specifically, each time a physician accepts a patient using a different payer, the physician has to enroll with that payer before reimbursement can be successfully authorized. Market research indicated that up to one-third of all providers experience changes in their enrollment profile each year, and these changes have to be updated with all their payers. The average physician is enrolled with 25 different payers, each of which may need information in slightly different formats or with slightly different types of data.
Remarkably, despite significant automation in other areas of the healthcare payment system, the entire physician enrollment process is done largely manually. There exists no electronic repository that consolidates physician information or the data requirements of all payers. As a consequence, for the more than 750,000 credentialed physicians in the US, each time they are enrolled with a physician network or have to interact with a new payer, physician information has to be manually input or modified.
Not surprisingly, the resulting enrollment process is lengthy and payment claims are frequently delayed. Further, payments are often improperly routed, causing cash flow and account settlement delays. The typical enrollment process currently takes between 2 weeks to 3 months to complete, costing both providers and payers time, payroll expense, and revenue.
See http://en.wikipedia.org/wiki/Health_care_in_the_United_States for a more detailed overview of the US healthcare payment system.
The Patient Protection and Affordable Care Act ("ACA" or Obamacare) provided a direct impetus to address non-strategic administrative procedures such as the manual enrollment process. In particular, a key provision of ACA specified that administrative costs for payers should not exceed 15% of the total costs (this is called the Medical Loss Ratio). As such, payers are now under significant pressure to simplify and streamline provider payment and claim reconciliation to reduce costs.!
It became clear that this non-strategic administrative waste was not only a growing opportunity crying out for a solution, but also something that spoke to Jim's core competency in using enterprise software to increase efficiency in an existing value chain.
If they could develop a platform solution recognized as a trusted, neutral third-party service at the center of physician enrollment process, they could bring significant value to all constituents in the system. Moreover, the type of system and team that Jim had helped build at Intralinks would be an ideal fit for enabling that change.
Jim was also able to partner with Ted Achtem and Mads Kvalsvik, two MIT graduates who had worked with Jim before and were looking to re-engage with the start-up experience. On the business side, Jim brought on Scott Soderstrom, who would head up finance and also work with Jim on business development. With the identification of a clear problem to be solved, and the skeleton of a team that could address it, Madaket Health was born. The first goal of the founders was to dramatically simplify and rationalize the process of physician enrollment, and then use that success to establish themselves as the most trusted electronic interface between physician groups and payers in the U.S. healthcare system.
Course of Treatment: the Madaket Health SaaS platform
While quietly confident of the opportunity at hand, the Madaket team appreciated that the path to success was far from clear as they faced many competing choices and would have to make tradeoffs. Even though they believed in the potential value of their solution, they still had to work through a large number of operational details, and there was tremendous value to be gained from working with partners in a more collaborative style. Since the ultimate adoption by both providers and payers would hinge on whether or not it could be integrated easily and seamlessly into a real-time operating environment, it was important to get detailed customer feedback at an early stage to ensure they were creating unique value in the existing marketplace. Building on his experiences with prior SaaS companies such as Intralinks, Jim realized that it would not be possible to identify
See http://www.cms.gov/CCIO/Programs-and-Initiatives/Health-Insurance-Market-Reforms/Medical-Loss-Ratio.html
for a detailed overview of PPACA's provisions. key features, identify required levels of functionality, and determine how to scale solutions without detailed and iterative customer feedback.
Thus, Jim and his team decided to operationalize Madaket as a software platform that connects providers and payers in a highly simplified yet secure fashion, using an architecture that would allow them to incorporate different functionality, features and positioning as they learned more about the market. They decided to build a rapid prototype of their solution, and then seek a collaborative partnership with either a Revenue Cycle Management ("RCM") company or a payer to gain feedback, optimize the platform, and demonstrate value. Their start-up costs were modest: $200,000 was raised from Fidelity Biosciences (with which Jim had a pre-existing relationship) and Lux Capital.
At its heart, the Madaket platform is a SaaS-based electronic repository of provider information that Madaket stores, packages and provides to payers. A two-sided platform, providers will submit their information to Madaket once. Madaket will automatically process and package the data and then provide each payer with only their desired data in their desired format. This feature is crucial in the conception of Madaket. While payers do not need to change their systems (or learn a new one), providers only have to learn one system-Madaket's-and then Madaket will handle the translation of data into usable, payer-specific formats. The Madaket SaaS platform provides support for highly configurable, complex data structures, including bi-directional electronic communication, and includes encryption for secure storage and transmission. At the same time, the service is "smart": data events will be automatically triggered by new enrollments, re-enrollments, and the like. In essence, Madaket offers a one-stop service; each provider will only have to provide their enrollment data once, and then will be able to initiate enrollment with any new payer in a seamless, automated manner as the need arises. After the completion of an early-stage software prototype, the Madaket team was able to attract the attention of a leading RCM ("Pioneer" v), which has been a pioneer in using technology to enhance revenue management and offer physician practice management services. After multiple meetings and discussions, Pioneer agreed to test their solution on a trial basis. These early interactions and enthusiasm to experiment by an industry leader provided an important reinforcement to Madaket's hypothesis that the enrollment process was an area where established companies faced a well-defined challenge, and that their proposed solution could add meaningful value.
Name disguised for confidentiality.
As they started to meet with potential customers and others in the industry, Jim was able to attract interest not only through his description of his potential solution but also through the integrated team that he was building to implement that solution. As a founder, Jim was well and had a track record of success in similar types of ventures. Equally importantly, over the course of his career, Jim had developed a network of developers and software engineers that he was able to rapidly bring on board and so build a cohesive team from Day 1. As specific examples, Ted Achtem and Mads Kvalsvik had both worked with Jim at Intralinks, and each had used that experience in other projects and ventures over time. Scott Soderstrom was also able to add value immediately and provide finance and business development support while the platform was being built. Based on their shared knowledge, the team was able to work quickly and efficiently in translating concepts and user requirements into running code that could be tested in an operational environment. While Ted focused primarily on the overall architecture of the software, Mads quickly assembled and managed a team in Pune, India, to ensure rapid execution and implementation.
Positive Symptoms: Early customer validation
The first beta of the platform went live in October 2013. A key milestone occurred when the software was used to enroll a real-world physician with an actual payer. Particularly against a backdrop where the "Obamacare" website debut was a source of national ridicule, the Madaket team was pleased to find that their hard work and careful integrative work with their customer had paid off: the integration had been a success, and Pioneer was able to begin using their software. The rollout to the rest of Pioneer would require persuading multiple decision-makers of the value of the new approach, but early indications were positive that, with time and effort, Madaket could solve a real problem for RCMs.
With this early validation, the Madaket team had felt sufficiently confident to roll out their solution to a wider audience. In 2014, they had begun discussions with two other large RCMs in hopes of securing them as customers.
One RCM, "Classic"v, was a large player, which had been relatively slow to adopt technology into its services. Classic faced a challenge in attracting top technical talent to its decades-old company headquartered in a city that did not have the entrepreneurial ecosystem of Silicon Valley or Boston. Classic served 300,000 providers, mainly composed of small private practices consisting of 1-5 physicians each. During initial conversations with Classic, they expressed significant interest in using Madaket to "leapfrog" their current processes towards a more technology-forward position. As Jim recalled, Classic executives told him "[digitization] is happening faster than we can deal with, and you're moving faster, so we will outsource it to you...We're putting our faith in you." In fact, they had even described that if Madaket's solution were to pass Classic's testing, they were planning to cancel existing vendor contracts, eliminate some clerical staff and reallocate some of its senior leadership to other strategic priorities.
The other RCM Madaket was focused on, was "Kingfish." v Similar to Classic, Kingfish had been relatively slower to adopt SaaS technology. Kingfish also served roughly 300,000 providers, however these were mainly made up of hospitals with 50+ providers each. The Madaket team believed that the value they could provide to the end users of Kingfish, hospital physicians, would be even greater for Kingfish's end clients than that of Classic and Pioneer. Jim for example, knew from his early interviews with hospital physicians that many of them also saw patients outside of the hospital (e.g. private practices at home, serving as part-time physicians for dance troupes or athletic teams).Thus, their reimbursement process was even more complicated (and therefore had even higher administrative costs) than the average provider.
Together, signing these RCMs would provide Madaket with access to around 600,000 providers in total, a significant majority of the overall market. Conversations with Pioneer, Classic and Kingfish had given the Madaket team greater confidence that they really were working on the right idea, and perhaps even more importantly, they were introducing it at the right time. While this was great news, at the same time however, they were also beginning to see competitive threats on the horizon.
The most notable competitive threat came from the Council for Affordable Quality Healthcare (CAQH), a non-profit alliance of health plans and trade associations that had developed Universal Provider Datasource (UPD), a database that facilitated the process of credentialing (the step before actual enrollment). According to CAQH, approximately 1 million physicians are included in the UPD, and more than 700 payers and provider organizations are currently using this adjacent service.l As well, CAQH, on behalf of their insurance industry stakeholders, was in the process of developing a potentially rival service that aimed at streamlining the enrollment process as well. Indeed, it is clear that Madaket is on the radar screen of CAQH: the CAQH enrollment service mock-up looks extremely similar to the design and approach that Jim and his team had provided to potential customers at an early stage of their development process. At some level, theCAQH move offers validation: Madaket clearly is addressing a real industry need, and
Name disguised for confidentiality.
See http://www.caqh.org/participatingorgs.php
for detailed list of organizations participating in the UPD
Jim and his team believed that it is unlikely that CAQH will actually be able to deploy a platform with the same level of functionality and robustness as Madaket. Moreover, Jim had recently attracted a former senior business development person from CAQH as a consultant to Madaket. With that said, they nonetheless recognize that they will be competing with CAQH as they try to build their customer base going forward.Though Jim and his team saw CAQH as their strongest potential threat, he believed other communications tools, and is seeking to link physicians to payer networks.?
The Prognosis: Madaket Health Going Forward
While no start-up experience is problem-free, Madaket has so far enjoyed a relatively smooth process. By the end of 2014 they had closed a Series A financing, developed a working customer-tested software platform, built an integrated team, demonstrated real value from their product, and closed a large contract with Classic.
In part because of that success and the validation of their business proposition, it was unclear how Madaket should position itself in the future. On the one hand, Madaket can concentrate its efforts on serving technology-based RCMs like Pioneer with the value proposition of helping them attract new physician groups and lower their costs. From a technical standpoint, working with the sophisticated IT team at companies like Pioneer would allow them to reinforce the value of RCN SaaS products through the integration of the Madaket process. However, it also seemed possible to Jim that Pioneer could perceive Madaket as only a small "feature" to its own product.
On the other hand, Madaket could focus on serving Classic and other similar RCMs, which have lagged behind on the technology front and are seeking ways to quickly catchup. The Classic executives expressed that the Madaket team was their preferred type of partner to help them improve the efficiency of their processes. Yet serving clients like Classic would also pose a challenge as a successful roll-out of Madaket could face some organizational resistance, as their platform allowed existing clerical employees to be replaced or reassigned. Jim worried if organizational frictions would slow down the integration of Madaket.
Finally, Kingfish was a third type of potential customer to focus on. Kingfish was particularly attractive as it served providers clustered together in hospitals, allowing Madaket to potentially achieve scale more quickly. Rapidly scaling could help Madaket build the critical mass they needed to both forestall competition and create value for both payers and providers alike. The challenge was that there are only a few RCMs modeled like Kingfish and their procurement processes were notoriously rigorous and lengthy. Jim was very proud of how far they had come. In a few short years, they had secured an enthusiastic first customer, built a technology that had a positive industry response, and a strong, growing team. He was now looking towards figuring out how to build on their early success to establish a position of long-term leadership in the healthcare payment industry and establish a durable competitive advantage for Madaket. As Jim considered the future of Madaket, he considered two key questions:
First, given that Madaket was now able to present potential customers with a battle-tested team that could meaningfully talk about how they solved the physician enrollment process, they were well poised to serve any of the three potential customer groups (RCMs including and similar to Pioneer, Classic and Kingfish). The question was which customer should they choose to concentrate on and why? How should they think about both the timing and sequencing of targeting other customers? Should they focus on achieving a successful roll-out with one customer or should they try to manage a staggered process across multiple organizations?
Second, what should Madaket's pricing strategy be? Should the pricing for RCMs like Pioneer be consistent with that of those like Classic and Kingfish? Should they price only one "side" of the market, by charging RCMs, or should they also consider charging payers as well? Or alternatively should they adopt a membership-type model, in which each customer -whether as an RCM or a payer-pays a monthly fee? The Madaket team's main objective was to find a pricing strategy that could allow them to earn significant margins on their development efforts while allowing the company to scale and grow quickly.
Appendix A: Brief Biography
Jim Dougherty
Jim Dougherty is a Senior Lecturer in Technological Innovation, Entrepreneurship, and Strategic Management at the MIT Sloan School of Management. Mr. Dougherty has extensive experience working directly with investors to execute highly successful turnarounds of troubled companies. Great Hill Partners recruited Dougherty to be their first-ever Operating Partner. He has stabilized and recapitalized such companies as Gartner, IntraLinks, Prodigy, and Smal Business ISP. At Lotus Development Corporation, Dougherty was the founder of eApps (Internet Division), and he created the NOTES: NEWSSTAND business publishing service, which was later sold successfully.
He is also an Adjunct Senior Fellow for Business and Foreign Policy at the Council on Foreign Relations. Dougherty holds a BA in government from Framingham State University, an MA in international economics from Columbia University, and a Graduate Certificate of Special Studies in finance and administration from Harvard University.
____________________________________________
References
1 InstaMed website, http://www.instamed.com/, accessed June 2019.
2 Rip Empson, "With 40% Of U.S. Doctors Signed On, Doximity's Jeff Tangney Reveals How The Social
Network For M.D.s Hit The Tipping Point," TechCrunch, March 3, 2014,
http://techcrunch.com/2014/03/15/with-40-of-u-s-doctors-signed-on-doximitys-jeff-tangney-reveals-how-
the-social-network-for-m-d-s-hit-the-tipping-point/, accessed June 2019
Introduction to Multimodal AI
**Abstract** : This paper provides an in-depth introduction to multimodal AI, exploring its concepts, applications, challenges, and future prospects. Multimodal AI holds the potential to revolutionize various fields by integrating and processing information from multiple modalities, offering more comprehensive and accurate understanding and interaction with the world.
**1. Introduction**
In recent years, the field of artificial intelligence (AI) has witnessed significant advancements, with multimodal AI emerging as a promising and transformative area. Multimodal AI refers to the ability of an AI system to understand, process, and generate information from multiple modalities such as text, images, audio, video, and sensor data. By combining and integrating these diverse sources of information, multimodal AI aims to provide a more holistic and comprehensive understanding of the world, enabling more intelligent and context-aware applications.
The motivation behind multimodal AI lies in the fact that in the real world, information is often presented in multiple forms simultaneously. Humans have the natural ability to seamlessly integrate and make sense of information from different modalities, such as recognizing a person by their face and voice or understanding a story by reading the text and viewing related images. However, traditional AI systems have typically focused on processing information from a single modality, limiting their capabilities and effectiveness in complex and dynamic environments.
Multimodal AI seeks to bridge this gap by developing algorithms and models that can handle and fuse information from multiple modalities, thereby mimicking human perception and cognition to a greater extent. This not only enhances the performance and accuracy of AI systems but also opens up new possibilities for applications in areas such as healthcare, robotics, autonomous driving, and human-computer interaction.
**2. Key Components and Techniques of Multimodal AI**
2.1 Data Representation and Preprocessing
One of the crucial steps in multimodal AI is the representation and preprocessing of data from different modalities. Different modalities have distinct characteristics and require appropriate methods for encoding and transforming into a common format that can be processed by the AI model. For example, images are typically represented as pixel arrays, while text is represented as sequences of words or vectors. Feature extraction techniques such as convolutional neural networks (CNNs) for images and recurrent neural networks (RNNs) or transformers for text are commonly used to extract meaningful features from the raw data.
In addition, data preprocessing techniques such as normalization, resampling, and noise reduction are applied to ensure the quality and consistency of the data. Moreover, aligning and synchronizing data from different modalities is often necessary to establish correspondence and temporal relationships, especially in cases where modalities are temporally correlated, such as audio and video.
2.2 Model Architectures
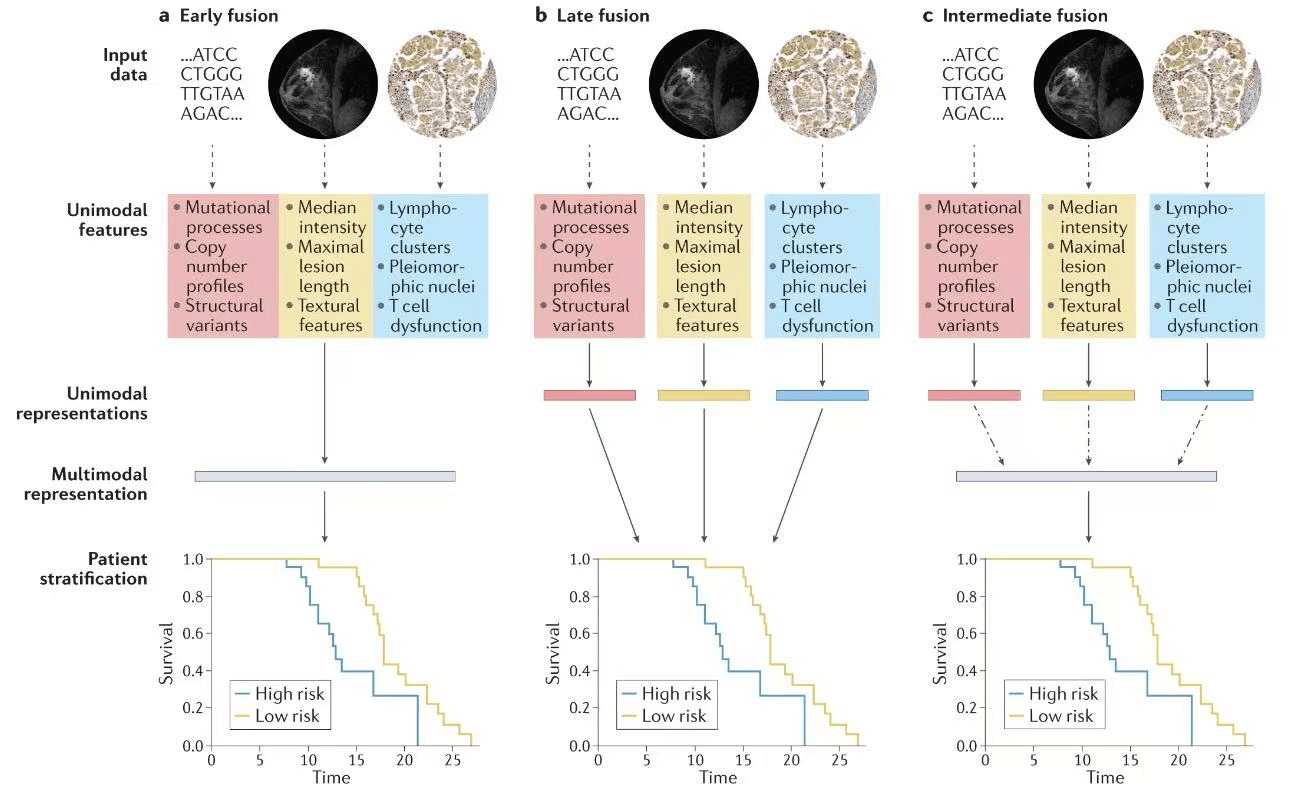
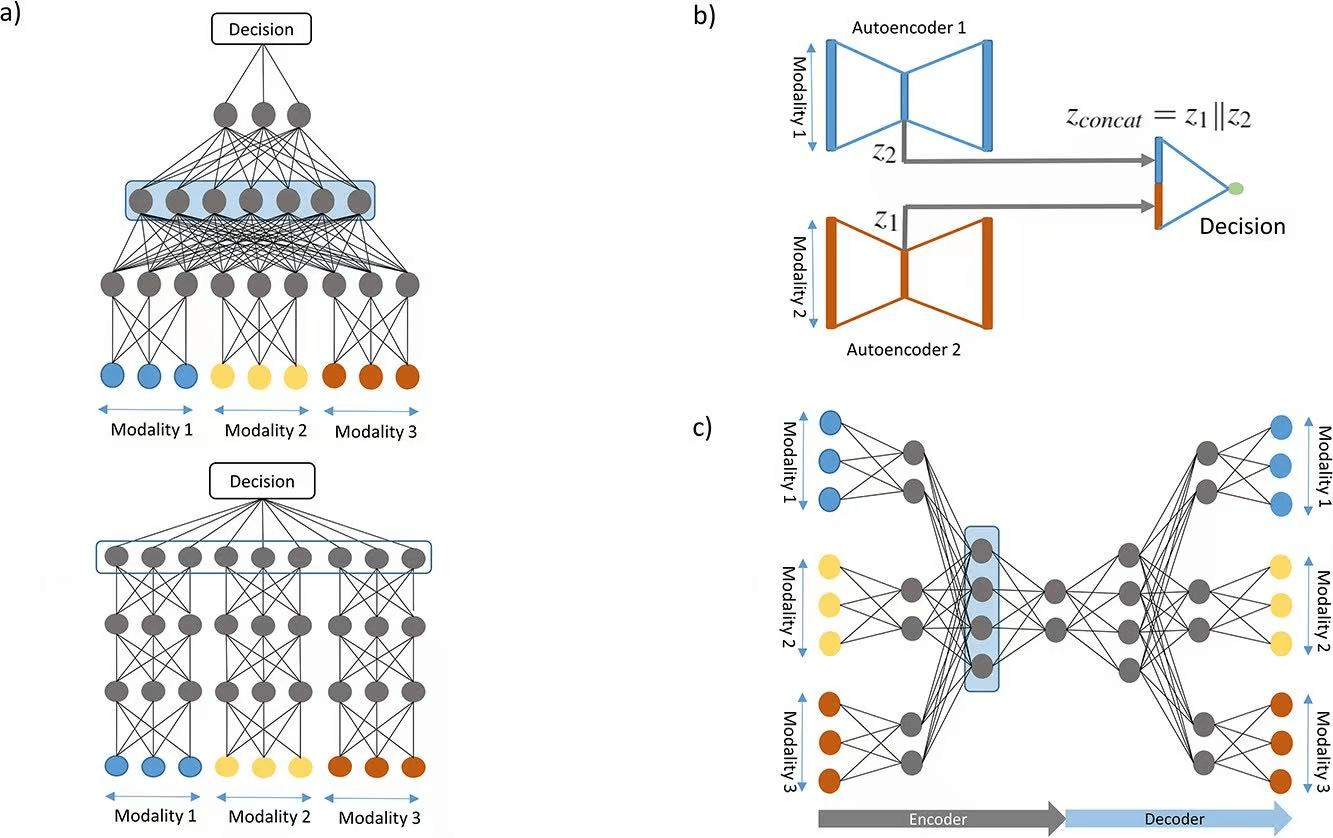
A wide range of model architectures have been developed for multimodal AI, including early fusion, late fusion, and intermediate fusion approaches. Early fusion combines data from different modalities at the input layer of the model, allowing for joint feature extraction and learning. Late fusion, on the other hand, processes each modality separately and combines the results at a later stage, typically through decision-level fusion. Intermediate fusion combines features at intermediate layers of the model, taking advantage of both low-level and high-level representations.
Deep learning architectures such as multi-modal convolutional neural networks (MCNNs), multi-modal recurrent neural networks (MRNNs), and multi-modal transformers have shown great potential in handling multimodal data. These architectures can capture complex interactions and dependencies between modalities and learn joint representations that capture the complementary information.
2.3 Attention Mechanisms
Attention mechanisms have become an important component in multimodal AI to selectively focus on relevant parts of the input data from different modalities. By computing attention weights based on the importance and relevance of different modalities or features, the model can dynamically allocate computational resources and capture the most salient information. Attention mechanisms help improve the performance and interpretability of multimodal models by highlighting the critical elements that contribute to the final output.
2.4 Cross-modal Learning and Alignment
Cross-modal learning aims to establish correspondences and mappings between different modalities to facilitate information transfer and sharing. Alignment techniques are used to align features or representations from different modalities in a common space, enabling comparisons and correlations. This can be achieved through methods such as canonical correlation analysis (CCA), deep canonical correlation analysis (DCCA), and adversarial learning.
2.5 Reinforcement Learning for Multimodal Interaction
Reinforcement learning can be employed in multimodal AI to optimize the interaction and decision-making process in dynamic environments. By defining rewards based on multimodal observations and actions, the agent can learn optimal strategies for interacting with the world and achieving specific goals. Reinforcement learning is particularly useful in applications such as robotics and autonomous systems where multimodal feedback is crucial for effective control and navigation.
**3. Applications of Multimodal AI**
3.1 Healthcare
Multimodal AI has significant potential in healthcare for disease diagnosis, treatment planning, and patient monitoring. By integrating medical images (such as X-rays, MRIs, and CT scans) with clinical text data (such as patient records and symptoms), AI systems can provide more accurate and comprehensive diagnoses. For example, combining image analysis with genomic data can help predict the prognosis and response to treatment for cancer patients.
In addition, multimodal AI can be used for real-time monitoring of patients' vital signs and behavioral patterns through sensors and video cameras, enabling early detection of anomalies and timely intervention. Virtual reality (VR) and augmented reality (AR) applications can also enhance medical training and surgical planning by providing immersive multimodal experiences.
3.2 Robotics and Autonomous Systems
In the field of robotics and autonomous systems, multimodal AI is essential for perception, navigation, and interaction with the environment. Robots need to integrate visual, auditory, and tactile information to understand their surroundings, make decisions, and perform tasks. For instance, a self-driving car must process images from cameras, lidar data, and audio cues to safely navigate on the road and avoid obstacles.
Multimodal human-robot interaction is another important application, where robots can understand human gestures, speech, and facial expressions to provide more natural and intuitive communication and assistance.
3.3 Media and Entertainment
Multimodal AI is transforming the media and entertainment industry. Content generation, recommendation systems, and immersive experiences are some of the areas where multimodal AI is making an impact. For example, generating realistic images, videos, and text based on given prompts or combining multiple media elements to create new forms of entertainment.
Recommender systems can take into account users' preferences across multiple modalities, such as their viewing history, listening habits, and social media activity, to provide personalized content suggestions. Virtual and augmented reality experiences can be enhanced by integrating multimodal feedback to create more immersive and engaging environments.
3.4 Education
In the education sector, multimodal AI can provide personalized learning experiences by analyzing students' learning behaviors, facial expressions, and verbal responses. Tutoring systems can adapt the teaching content and methods based on multimodal feedback to better meet the individual needs of students. Additionally, multimodal educational resources such as interactive textbooks with multimedia elements can enhance the learning process.
3.5 Smart Homes and Internet of Things (IoT)
Multimodal AI can enable smart homes and IoT devices to understand and respond to users' multimodal commands and context. For example, a smart home system can integrate voice commands, sensor data, and visual information to adjust the lighting, temperature, and security settings based on the user's presence and activities.
**4. Challenges and Limitations of Multimodal AI**
4.1 Data Heterogeneity and Compatibility
Handling the heterogeneity and incompatibility of data from different modalities is a significant challenge. Different modalities may have different resolutions, sampling rates, and semantic structures, making it difficult to align and fuse them seamlessly. Additionally, obtaining large-scale and labeled multimodal datasets is often costly and time-consuming.
4.2 Computational Complexity
Multimodal AI models often require significant computational resources for training and inference due to the large amount of data and complex model architectures. This can limit their practical application in resource-constrained environments and real-time systems.
4.3 Interpretability and Explainability
Interpretability and explainability of multimodal AI models are crucial, especially in critical applications such as healthcare and autonomous systems. Understanding how the model combines and makes decisions based on multimodal information is challenging, and developing methods to provide transparent and interpretable results is an active area of research.
4.4 Privacy and Security
Multimodal data often contains sensitive personal information, raising concerns about privacy and security. Ensuring the protection of data during collection, storage, and processing is of utmost importance to prevent unauthorized access and misuse.
4.5 Generalization and Robustness
Multimodal AI models need to demonstrate generalization and robustness across different modalities and domains. They should be able to handle variations and noise in the input data and perform well in unseen or novel situations.
**5. Future Directions and Outlook**
5.1 Advancements in Model Architectures and Algorithms
Continued research and innovation in model architectures and algorithms will drive the development of more efficient and effective multimodal AI systems. Hybrid models that combine different types of neural networks and other techniques are likely to emerge, along with improvements in attention mechanisms, cross-modal learning, and reinforcement learning.
5.2 Integration with Other Technologies
Multimodal AI is expected to integrate with emerging technologies such as 5G networks, edge computing, and quantum computing to overcome computational and latency limitations. This will enable real-time processing and deployment of multimodal AI applications in various domains.
5.3 Ethical and Societal Considerations
As multimodal AI becomes more pervasive, ethical and societal issues such as bias, discrimination, and the impact on employment need to be addressed. Guidelines and regulations should be established to ensure the responsible and beneficial use of multimodal AI technologies.
5.4 Interdisciplinary Research and Collaboration
Multimodal AI requires collaboration across multiple disciplines, including computer science, neuroscience, psychology, and linguistics. Interdisciplinary research efforts will help deepen our understanding of human multimodal perception and cognition and inspire new ideas and approaches in multimodal AI.
In conclusion, multimodal AI represents a significant advancement in the field of artificial intelligence, offering the potential to unlock new capabilities and applications across various domains. While there are challenges to overcome, ongoing research and technological progress hold promise for creating more intelligent and context-aware systems that can better interact and understand the complex multimodal world we live in. The future of multimodal AI is bright, and its impact is likely to be profound in shaping the way we live, work, and interact with technology.
 \
\
Multimodal AI Data Collection: Challenges, Techniques, and Implications
**Abstract**: This paper explores the multifaceted landscape of multimodal AI data collection. It delves into the challenges associated with obtaining and integrating data from multiple modalities, presents various techniques and strategies for effective collection, and discusses the significant implications for the advancement of multimodal artificial intelligence. The aim is to provide a comprehensive understanding of this crucial aspect of multimodal AI research and development.
**1. Introduction**
Multimodal AI, which involves the integration and processing of information from multiple sources such as text, images, audio, and video, has emerged as a powerful approach in the field of artificial intelligence. The success of multimodal AI systems heavily relies on the quality, quantity, and diversity of the collected data. However, collecting multimodal data presents unique challenges that require careful consideration and innovative solutions.
**2. Challenges in Multimodal AI Data Collection**
2.1 Heterogeneity of Data Formats
Multimodal data comes in a wide variety of formats, each with its own characteristics and requirements for collection, storage, and processing. Text data may be in structured or unstructured form, images can have different resolutions and color spaces, and audio data may have varying sampling rates and encoding formats. This heterogeneity makes it difficult to establish a unified framework for data collection and management.
2.2 Synchronization and Alignment
When dealing with multiple modalities, ensuring temporal or semantic alignment is crucial. For example, in a video with accompanying audio, the speech and visual cues need to be precisely synchronized for accurate analysis. Achieving this alignment can be complex, especially when data is collected from different sources or devices with varying timestamps and sampling frequencies.
2.3 Labeling and Annotation
Accurate labeling and annotation of multimodal data is essential for training effective AI models. However, this task is often labor-intensive and requires domain expertise. Moreover, providing consistent and comprehensive labels across multiple modalities adds an additional layer of complexity.
2.4 Privacy and Ethical Concerns
Collecting multimodal data often involves personal and sensitive information, raising significant privacy and ethical issues. Ensuring the protection of individuals' rights while obtaining useful data for research and development is a delicate balance that requires strict adherence to legal and ethical guidelines.
2.5 Data Quality and Noise
Multimodal data is prone to various types of noise and quality issues. For instance, images may be blurry, audio may have background noise, or text may contain errors. Dealing with and minimizing the impact of such noise on the data collection process is a challenge that affects the reliability and validity of the collected data.
**3. Techniques for Multimodal AI Data Collection**
3.1 Sensor Fusion
The use of multiple sensors to collect data simultaneously can help capture different modalities in a coordinated manner. For example, combining cameras, microphones, and inertial measurement units (IMUs) in a mobile device can provide a rich set of multimodal data related to the device's environment and user interactions.
3.2 Crowdsourcing
Leveraging the power of the crowd to collect and label multimodal data has become a common practice. Platforms can be set up to engage a large number of workers to contribute data or perform annotation tasks. However, quality control and ensuring the reliability of crowdsourced data are important considerations.
3.3 Simulation and Virtual Environments
Creating synthetic multimodal data through simulations and virtual environments offers a controlled and customizable approach to data collection. This can be useful when real-world data is scarce or when specific scenarios need to be generated for experimentation.
3.4 Preprocessing and Feature Extraction
Applying appropriate preprocessing techniques to clean, normalize, and transform the raw multimodal data is an important step. Feature extraction methods can be employed to extract relevant and salient features from each modality, making the data more manageable and suitable for analysis.
3.5 Active Learning
In active learning, the model selectively requests labels for the most informative data points, reducing the amount of labeled data needed while maintaining or improving the model's performance. This can be particularly useful in multimodal data collection where labeling efforts are expensive.
**4. Implications of Multimodal AI Data Collection**
4.1 Enhanced Model Performance
High-quality and diverse multimodal data leads to more accurate and robust AI models. The integration of multiple modalities provides complementary information, allowing the model to make more comprehensive and informed predictions.
4.2 New Application Domains
Enabling the development of applications in areas such as healthcare (e.g., medical image analysis combined with clinical notes), autonomous driving (sensor fusion for better perception), and human-computer interaction (natural multimodal interfaces).
4.3 Insights into Human Perception and Cognition
Studying multimodal data collection and processing can offer valuable insights into how humans perceive and understand the world through multiple senses, contributing to the development of more human-like AI systems.
4.4 Ethical and Social Impact
The collection and use of multimodal data raise ethical and social questions related to privacy, bias, and the potential for discrimination. Addressing these issues is crucial to ensure the responsible and beneficial deployment of multimodal AI technologies.
**5. Case Studies**
5.1 Healthcare: Medical Imaging and Electronic Health Records
In the healthcare domain, combining medical images (such as X-rays, MRIs) with electronic health records (text-based patient information) has shown potential in improving disease diagnosis and treatment planning. The challenge lies in aligning and integrating the heterogeneous data and ensuring the privacy of patient information.
5.2 Autonomous Vehicles: Sensor Fusion for Object Detection
Autonomous vehicles rely on the fusion of data from cameras, lidar, radar, and other sensors to accurately detect and classify objects in the surrounding environment. Collecting and processing this multimodal data in real-time and under various conditions is critical for safe driving.
5.3 Entertainment: Virtual and Augmented Reality
In the entertainment industry, creating immersive virtual and augmented reality experiences requires the collection of multimodal data including visual, auditory, and haptic information. This data is used to build realistic and interactive virtual worlds.
**6. Conclusion**
Multimodal AI data collection is a complex but essential task that holds great promise for advancing the field of artificial intelligence. Addressing the challenges through innovative techniques and strategies will lead to the development of more powerful and useful multimodal AI systems. However, it is imperative to do so while considering the ethical and social implications to ensure that the benefits of this technology are realized in a responsible and sustainable manner. Future research should focus on further improving data collection methods, enhancing data quality and annotation, and exploring new application areas where multimodal AI can make a significant impact.
Data Integration in Multisensory AI: An In-Depth Analysis
**Abstract**: This paper offers a thorough examination of data integration within the realm of multisensory artificial intelligence (AI). It delves into the importance, methodologies, obstacles, and practical applications associated with data integration in this context. The goal is to provide a comprehensive overview of this pivotal area that is propelling advancements in the field.
**1. Introduction**
Multisensory AI, which encompasses the integration and processing of information from various sources such as text, images, audio, and video, has garnered considerable attention in recent years. The capability to integrate and utilize data from diverse origins enhances accuracy and depth of understanding, leading to better decision-making and performance. Data integration is central to achieving this synergy.
**2. Importance of Data Integration in Multisensory AI**
Data integration facilitates the complementary combination of information from different sources. Each source often captures unique aspects of a phenomenon, and by integrating them, a more complete and detailed understanding can be achieved. For instance, in healthcare, merging medical imaging with patient records and genomic data can lead to more accurate diagnoses and treatment plans.
It also aids in overcoming the limitations of individual data sources. Some sources may contain noise, ambiguity, or incomplete information, but when integrated with others, these issues can be mitigated. Furthermore, data integration enables the discovery of hidden patterns and correlations that might not be apparent when analyzing each source separately.
**3. Methods of Data Integration in Multisensory AI**
3.1 Early Integration
This method combines raw data from different sources at an early stage of the processing pipeline. Features are extracted and merged before being input into the learning model. For example, in image and text classification, the pixel values of images and word embeddings of text can be concatenated and used as input.
3.2 Late Integration
In late integration, data sources are processed independently, and the results are combined later. Decision-level integration is a common approach where predictions or outputs from each source are combined using methods like averaging, weighted averaging, or majority voting.
3.3 Intermediate Integration
This technique merges features or representations of data sources at intermediate layers of the model. It balances between early and late integration, allowing for the capture of both low-level and high-level interactions between the sources.
3.4 Deep Learning-Based Approaches
With the rise of deep learning, techniques such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been utilized for feature extraction and integration. Attention mechanisms have also proven effective in selectively focusing on the most relevant parts of the multisensory data.
**4. Challenges in Data Integration for Multisensory AI**
4.1 Data Heterogeneity
Different data sources often exhibit varying characteristics in terms of structure, resolution, and semantics. Aligning and integrating these heterogeneous sources poses a significant challenge.
4.2 Synchronization Problems
When dealing with time-series data, ensuring proper synchronization between sources is crucial. Misalignment can result in incorrect integration and inaccurate outcomes.
4.3 Computational Complexity
Integrating large volumes of multisensory data and training complex integration models can be computationally intensive, requiring efficient algorithms and hardware resources.
4.4 Overfitting and Generalization
Care must be taken to avoid overfitting to the training data and ensure that the integration model generalizes well to new and unseen data.
**5. Applications of Data Integration in Multisensory AI**
5.1 Healthcare
In disease diagnosis, data integration can combine medical imaging, clinical data, and genomic information for more precise predictions. It also finds use in patient monitoring and personalized medicine.
5.2 Autonomous Driving
Integrating data from cameras, lidar, radar, and other sensors aids in object detection, path planning, and decision-making for safe and efficient driving.
5.3 Human-Computer Interaction
Multisensory data integration enables more natural and intuitive interaction, such as combining speech, gestures, and facial expressions for enhanced user experiences.
5.4 Media and Entertainment
In content creation and recommendation systems, integrating data from multiple sources can provide personalized and engaging experiences.
**6. Conclusion**
Data integration in multisensory AI is a critical area with immense potential for transforming various domains. Addressing the challenges and leveraging appropriate methods can lead to significant advancements. Continued research and innovation in this field are essential for unlocking the full capabilities of multisensory AI and driving further progress in applications that rely on the seamless integration of diverse data sources.
The future of data integration in multisensory AI looks promising, with the potential for more advanced methods, improved performance, and broader applications that will shape how we interact with and utilize information in a multisensory world.
Research Report on Multimodal AI Interpretability
**Abstract**: This research report delves into the interpretability of multimodal artificial intelligence (AI), a critical aspect that has garnered significant attention in recent years. The report provides an in-depth analysis of the current state, challenges, solutions, and future trends in this domain. By synthesizing the latest research findings and practical applications, it offers valuable insights for researchers, developers, and stakeholders interested in advancing the field of multimodal AI interpretability. The ultimate goal is to foster trust, accountability, and ethical use of AI systems by enhancing our understanding of how these models operate.
**1. Introduction**
Multimodal AI, which integrates and processes information from multiple modalities such as text, images, audio, and video, has demonstrated remarkable potential across various industries. From healthcare diagnostics to autonomous driving, multimodal AI has shown its ability to handle complex tasks more effectively than single-modality systems. However, the complexity and opacity of these models have raised concerns about their interpretability. Understanding how these models make decisions and generate outputs is crucial for ensuring trust, accountability, and the safe and ethical use of AI. For instance, in healthcare, clinicians need to trust the AI's recommendations before making critical decisions. In autonomous vehicles, passengers and regulators must be confident that the system can explain its actions in real-time.
**2. Current State of Multimodal AI Interpretability**
Recent advancements in multimodal AI interpretability have made significant strides in developing methods to explain these complex models. Feature visualization techniques, such as heatmaps and saliency maps, have been employed to illustrate how different modalities contribute to the final decision. For example, in image recognition tasks, these techniques can highlight which parts of an image are most influential in the model's decision-making process. Attention mechanisms have also been used to emphasize specific parts of the input data, providing insights into the model's focus areas. Additionally, some researchers have explored model decomposition approaches, breaking down the model into simpler components to understand its internal workings better.
In practical applications, multimodal AI interpretability has started to play a pivotal role in several domains. In healthcare, explaining diagnoses based on multimodal patient data—such as medical records, imaging scans, and genetic information—is essential for building clinicians' trust and aiding decision-making. In the field of autonomous driving, understanding the vehicle's multimodal perception and decision-making processes is crucial for public acceptance and safety. For instance, if an autonomous vehicle makes a sudden stop, it should be able to explain why it did so, whether due to detecting an obstacle or interpreting traffic signals.
**3. Challenges in Multimodal AI Interpretability**
3.1 Data Heterogeneity and Complexity
Multimodal data often exhibit diverse characteristics, including different data structures, semantic meanings, and temporal dynamics. For example, integrating textual data with visual data requires handling both discrete symbols and continuous features. Integrating and making sense of this heterogeneous data poses significant challenges in interpretability. Each modality may have its own unique properties, and aligning them in a meaningful way can be difficult. Moreover, the temporal dynamics of certain modalities, such as video or audio streams, add another layer of complexity.
3.2 Model Architecture Complexity
Deep neural networks commonly used in multimodal AI are highly complex, with layers upon layers of interconnected nodes. This complexity makes it difficult to trace and explain the decision-making process. The interactions and fusions of multiple modalities within these models are often not straightforward to understand. For instance, in a multimodal model that combines text and images, it can be challenging to determine how much weight the model assigns to each modality when making a decision. Furthermore, the black-box nature of deep learning models exacerbates this issue, as the internal workings remain opaque even to the developers.
3.3 Lack of Unified Evaluation Metrics
There is currently no consensus on standardized evaluation metrics for multimodal AI interpretability. Different studies use varying criteria to assess interpretability, making it challenging to compare and benchmark different methods and models. For example, one study might focus on the accuracy of explanations, while another might prioritize the comprehensibility of the explanations to human users. Without a unified framework, it becomes difficult to objectively evaluate the effectiveness of interpretability techniques.
**4. Proposed Solutions and Approaches**
4.1 Interpretable Model Designs
Developing multimodal AI models with inherent interpretability features can significantly enhance the transparency of these systems. One approach is to use simple and transparent architectures, such as decision trees or rule-based systems, which are easier to understand and explain. Another approach is to incorporate rule-based components into deep learning models, allowing for a hybrid architecture that balances performance and interpretability. For example, a model could use a neural network for feature extraction but rely on a rule-based system for decision-making, making it easier to trace the reasoning behind the output.
4.2 Visualization and Interaction Tools
Creating intuitive visualization interfaces and interaction methods allows users to explore and understand the multimodal data and model behavior. Interactive feature maps, decision trees, and saliency maps can provide users with a visual representation of how the model processes information. For instance, in a healthcare application, a clinician could interact with a heatmap that highlights the most relevant parts of a patient's medical record or imaging scan. These tools can also facilitate communication between technical experts and non-technical stakeholders, ensuring that everyone has a clear understanding of the model's behavior.
4.3 Hybrid Interpretability Methods
Combining multiple interpretability techniques can provide a more comprehensive understanding of multimodal AI models. For example, combining feature visualization with model decomposition can offer both a high-level overview of the model's decision-making process and a detailed breakdown of its internal workings. This hybrid approach can help address the limitations of individual methods, providing a more robust explanation of the model's behavior. Additionally, using multiple techniques can increase the confidence in the interpretations, as they can cross-validate each other.
**5. Future Trends and Prospects**
5.1 Integration with Cognitive Science
Incorporating insights from cognitive science can inspire new approaches to multimodal AI interpretability. Cognitive science studies how humans process and interpret information from multiple sources, which can provide valuable insights into designing interpretable AI systems. For example, understanding how humans integrate visual and auditory cues can inform the development of AI models that mimic this process. Additionally, cognitive science can help identify the types of explanations that are most comprehensible to humans, ensuring that AI-generated explanations are user-friendly and actionable.
5.2 Ethical and Legal Considerations
As the demand for interpretability grows, there will be an increasing need for ethical and legal guidelines to ensure the responsible use and interpretation of multimodal AI. For instance, in healthcare, there may be regulations requiring AI systems to provide transparent explanations for their decisions. Similarly, in autonomous driving, there may be legal requirements for vehicles to explain their actions in real-time. Developing these guidelines will require collaboration between technologists, policymakers, and ethicists to strike a balance between innovation and accountability.
5.3 Real-time and Dynamic Interpretability
In scenarios where decisions need to be made in real-time, such as in autonomous systems or emergency response applications, achieving real-time and dynamic interpretability will become a critical requirement. Traditional interpretability methods often involve post-hoc analysis, which may not be suitable for time-sensitive applications. Therefore, there is a growing need for interpretability techniques that can provide immediate and continuous explanations. For example, an autonomous vehicle should be able to explain its actions as it navigates through traffic, ensuring that passengers and regulators can understand its decision-making process in real-time.
**6. Conclusion**
Multimodal AI interpretability is a rapidly evolving field that holds great promise for improving the trustworthiness and usability of multimodal AI systems. Addressing the existing challenges and exploring innovative solutions will not only advance the field of AI but also ensure its safe and beneficial integration into various aspects of our lives. Continued research and collaboration across different disciplines are essential to unlock the full potential of multimodal AI interpretability. It is important to note that this is an ongoing area of research, and future developments may bring new insights and solutions that further enhance our understanding and application of multimodal AI interpretability. As the field progresses, we can expect to see more sophisticated and reliable interpretability methods that bridge the gap between complex AI models and human understanding.
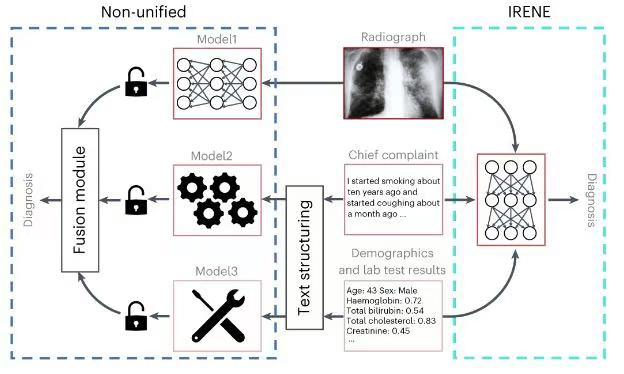
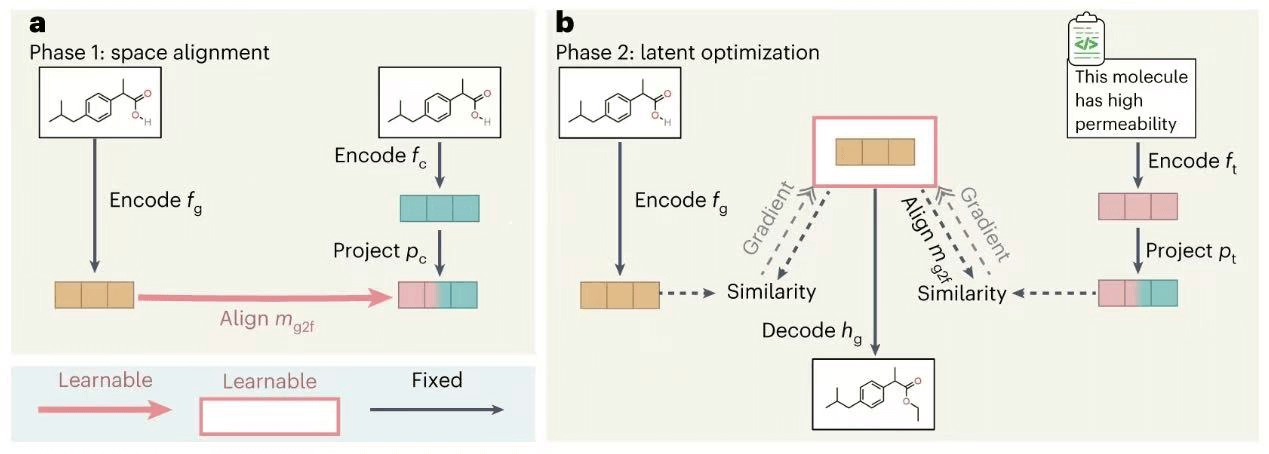
Report on Multimodal AI Applications
Report on Multimodal AI Applications
**Abstract**: This report provides a comprehensive examination of the diverse applications of multimodal artificial intelligence (AI). It explores how multimodal AI is revolutionizing various sectors, including healthcare, education, entertainment, and more. The aim is to highlight the potential and impact of multimodal AI across different domains and offer insights into its future prospects.
**1. Introduction**
Multimodal AI, which integrates and processes information from multiple modalities such as text, images, audio, and video, has emerged as a transformative force in the field of artificial intelligence. By combining and analyzing data from diverse sources, multimodal AI enables a more comprehensive and accurate understanding, leading to innovative applications and solutions. This integration not only enhances the performance of AI systems but also opens up new possibilities for addressing complex challenges in various industries.
**2. Multimodal AI in Healthcare**
2.1 Medical Diagnosis
Multimodal AI is transforming medical diagnosis by integrating medical images (e.g., X-rays, MRIs, CT scans) with patient clinical data, genomic information, and real-time physiological data from biosensors. For instance, in cancer diagnosis, the integration of tumor imaging with genomic profiles can provide more precise predictions of treatment responses, enhancing personalized medicine. This approach allows for earlier detection and more effective treatment plans, ultimately improving patient outcomes.
2.2 Telemedicine
In the era of telemedicine, multimodal AI facilitates remote patient monitoring through video consultations, wearable devices that collect physiological data, and voice analysis for early detection of health issues. This approach ensures timely and personalized care, particularly beneficial for patients in remote or underserved areas. By leveraging these technologies, healthcare providers can offer continuous monitoring and intervention, reducing hospital readmissions and improving overall patient management.
2.3 Surgical Assistance
During surgeries, multimodal AI systems fuse information from endoscopic cameras, real-time vital sign monitors, and preoperative surgical planning data to assist surgeons in making informed decisions, thereby reducing surgical risks and improving outcomes. Advanced algorithms analyze intraoperative data in real-time, providing surgeons with critical insights and recommendations that enhance procedural precision and safety.
**3. Multimodal AI in Education**
3.1 Personalized Learning
Multimodal AI can create personalized learning experiences by integrating student performance data, learning styles, and emotional responses. For example, by analyzing facial expressions and voice tones during online learning sessions, the system can dynamically adjust the difficulty level and pace of the curriculum to better meet individual needs. This adaptive approach fosters a more engaging and effective learning environment, catering to the unique requirements of each student.
3.2 Intelligent Tutoring Systems
These systems combine text-based questions and answers with visual aids and audio explanations to provide more effective learning support. They can also adapt to the student's preferred mode of learning—whether visual, auditory, or kinesthetic—thereby enhancing educational outcomes. Through continuous assessment and feedback, intelligent tutoring systems ensure that students receive targeted assistance, promoting deeper understanding and retention of material.
3.3 Language Learning
Multimodal AI enhances language learning by integrating speech recognition, text analysis, and visual context. For instance, language learning apps can provide real-time feedback on pronunciation and grammar while displaying relevant images or videos to improve comprehension and retention. This multi-sensory approach supports both novice and advanced learners, facilitating faster and more effective language acquisition.
**4. Multimodal AI in Entertainment**
4.1 Content Generation
Multimodal AI is used to generate new content such as music, videos, and stories by combining patterns and themes from existing works. It can also create immersive virtual and augmented reality experiences by integrating multiple sensory inputs, thereby enhancing user engagement. These capabilities allow for the creation of highly personalized and interactive entertainment experiences that captivate audiences and foster creativity.
4.2 Personalized Recommendations
By analyzing user behavior across multiple platforms such as streaming services, social media, and gaming, multimodal AI provides personalized content recommendations. It takes into account not only what users watch or play but also their reactions and comments, ensuring a more tailored experience. This level of personalization increases user satisfaction and loyalty, driving higher engagement and consumption of digital content.
4.3 Interactive Entertainment
In interactive games and experiences, multimodal AI responds to player actions, voice commands, and gestures, creating more engaging and dynamic gameplay. This interactivity enhances user immersion and satisfaction, making entertainment experiences more compelling and memorable. Advanced AI-driven features enable real-time adaptation to user preferences, offering a seamless and intuitive interface for players.
**5. Multimodal AI in Autonomous Systems**
5.1 Autonomous Vehicles
In self-driving cars, multimodal AI fuses data from cameras, lidar, radar, and GPS to perceive the environment, make driving decisions, and avoid obstacles. It also integrates with in-vehicle infotainment systems to provide a seamless and personalized driving experience, enhancing safety and convenience. Robust algorithms process vast amounts of sensor data in real-time, enabling autonomous vehicles to navigate complex urban environments with high accuracy and reliability.
5.2 Drones and Robotics
Multimodal AI enables drones and robots to navigate complex environments, interact with humans, and perform tasks by processing visual, auditory, and tactile information. For example, delivery drones can identify obstacles and recipients based on multiple sensory cues, improving efficiency and reliability. In industrial settings, robotic systems equipped with multimodal AI can autonomously execute intricate tasks, increasing productivity and reducing human error.
**6. Challenges and Limitations of Multimodal AI Applications**
6.1 Data Privacy and Security
The collection and processing of multimodal data raise significant privacy concerns. Ensuring the security and protection of sensitive personal information is crucial to maintaining trust and compliance with regulations. Implementing robust encryption and access control mechanisms is essential to safeguard data integrity and confidentiality.
6.2 Interoperability and Standardization
Different modalities often have varying data formats and standards, making integration and communication between systems challenging. Establishing common standards and protocols is necessary for seamless multimodal AI applications. Collaboration among industry stakeholders is vital to develop standardized frameworks that facilitate interoperability and scalability.
6.3 Ethical Considerations
The use of multimodal AI in decision-making processes, such as healthcare and autonomous systems, raises ethical questions regarding accountability, fairness, and potential biases. Addressing these concerns is essential for responsible AI deployment. Transparent and explainable AI models can help mitigate ethical risks and build public confidence in AI technologies.
6.4 Computational Resources
Processing and analyzing large amounts of multimodal data require significant computational power and infrastructure. Efficient resource management is critical to ensure scalability and performance. Advances in hardware and cloud computing technologies are crucial for supporting the growing demands of multimodal AI applications.
**7. Future Outlook and Conclusion**
The future of multimodal AI applications looks promising, with continuous advancements in technology and increasing adoption across various sectors. However, addressing the challenges and limitations is essential for ensuring the responsible and beneficial use of multimodal AI. Continued research and development, along with ethical and regulatory frameworks, will shape the trajectory of multimodal AI and unlock its full potential for the betterment of society.
In conclusion, multimodal AI is opening up new frontiers in numerous fields, offering innovative solutions and transforming the way we live, work, and interact. The potential is vast, but it requires careful management and strategic development to realize its true benefits.